Struts2 框架——阻止表单重复提交
本文共 204 字,大约阅读时间需要 1 分钟。
阻止表单重复提交
实现过程:
1.在from表单中,使用s标签会有一组UUID值;
<%@taglib uri="/struts-tags" prefix="s" %>

2.在struts.xml中配置拦截器,引入拦截类;
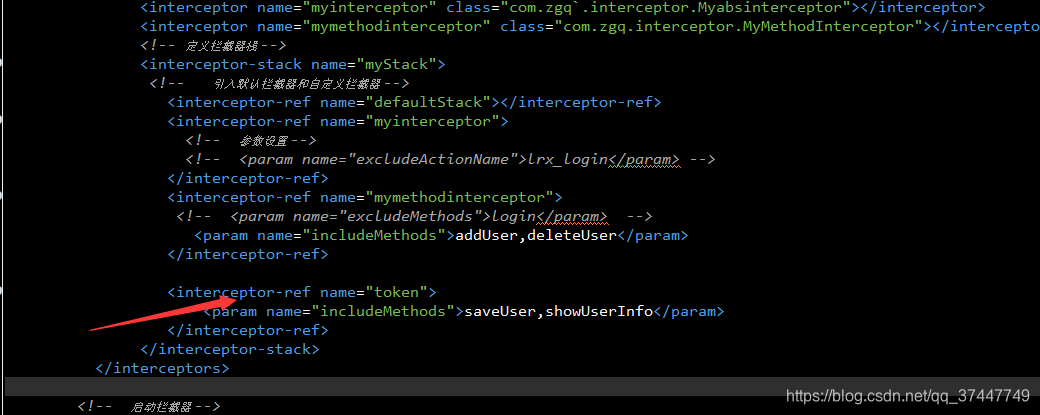
3.在jsp 页面引入struts标签,UUID存放页面的表单中;
阻止后跳转到》》》
<result name="invalid.token">/index.jsp</result>
转载地址:http://tdkcz.baihongyu.com/
你可能感兴趣的文章
mysqldump 导出中文乱码
查看>>
mysqldump 导出数据库中每张表的前n条
查看>>
mysqldump: Got error: 1044: Access denied for user ‘xx’@’xx’ to database ‘xx’ when using LOCK TABLES
查看>>
Mysqldump参数大全(参数来源于mysql5.5.19源码)
查看>>
mysqldump备份时忽略某些表
查看>>
mysqldump实现数据备份及灾难恢复
查看>>
mysqldump数据库备份无法进行操作只能查询 --single-transaction
查看>>
mysqldump的一些用法
查看>>
mysqli
查看>>
MySQLIntegrityConstraintViolationException异常处理
查看>>
mysqlreport分析工具详解
查看>>
MySQLSyntaxErrorException: Unknown error 1146和SQLSyntaxErrorException: Unknown error 1146
查看>>
Mysql_Postgresql中_geometry数据操作_st_astext_GeomFromEWKT函数_在java中转换geometry的16进制数据---PostgreSQL工作笔记007
查看>>
mysql_real_connect 参数注意
查看>>
mysql_secure_installation初始化数据库报Access denied
查看>>
MySQL_西安11月销售昨日未上架的产品_20161212
查看>>
Mysql——深入浅出InnoDB底层原理
查看>>
MySQL“被动”性能优化汇总
查看>>
MySQL、HBase 和 Elasticsearch:特点与区别详解
查看>>
MySQL、Redis高频面试题汇总
查看>>